Generative World Modelling for Humanoids: 1X World Model Challenge Technical Report
10 Oct, 2025·
 ,,,,,,·
0 min read
,,,,,,·
0 min read
Riccardo Mereu
Equal contribution
Aidan Scannell
Equal contribution
,Yuxin Hou
Yi Zhao
Aditya Jitta
Antonio Dominguez
Luigi Acerbi
Amos Storkey
Paul Chang
Abstract
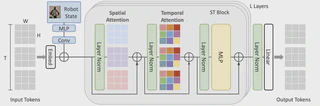
World models are a powerful paradigm in AI and robotics, enabling agents to reason about the future by predicting visual observations or compact latent states. The 1X World Model Challenge introduces an open-source benchmark of real-world humanoid interaction, with two complementary tracks: sampling, focused on forecasting future image frames, and compression, focused on predicting future discrete latent codes. For the sampling track, we adapt the video generation foundation model Wan-2.2 TI2V-5B to video-state-conditioned future frame prediction. We condition the video generation on robot states using adaLN-Zero, and further post-train the model using LoRA. For the compression track, we train a Spatio-Temporal Transformer model from scratch. Our models achieve 23.0 dB PSNR in the sampling task and a Top-500 CE of 6.6386 in the compression task, securing 1st place in both challenges.
Type
Publication
arXiv preprint arXiv:2510.07092