Beyond Mamba SSMs: Parallel Kalman Filters as Scalable Primitives for Language Modelling
12 Nov, 2025·, ,,·
0 min read
,,·
0 min read
Vaisakh Shaj
Cameron Barker
Aidan Scannell
Elliot J. Crowley
Amos Storkey
Abstract
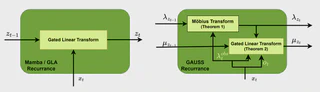
State-space language models, including Mamba and other gated linear attention (GLA) variants, have challenged transformer based auto-regressive models, at least partly because of their linear complexity and highly parallel training. On the other hand, probabilistic latent state space models, with inference via the Kalman filter, have been a bedrock of sequence modelling for decades but are typically applied recursively, making them appear unsuitable for parallel training. In this paper, we show that by reparameterizing the Kalman filter in information form, its updates can be unrolled efficiently, allowing for scalable parallel training in modern hardware. Building on this, we introduce the GAUSS layer (Gating As Uncertainties in State Spaces), a neural sequence modelling primitive. We show that GAUSS provides strictly more expressive non-linear updates and gating mechanisms than GLA variants while retaining their computational benefits. Finally, in a seemingly counterintuitive application of language modeling, we show that GAUSS compete with modern SSMs and GLAs on several discrete token manipulation tasks, and holds promise as a viable probabilistic primitive for language modelling.
Type
Publication
EurIPS 2025 Workshop: Epistemic Intelligence in Machine Learning