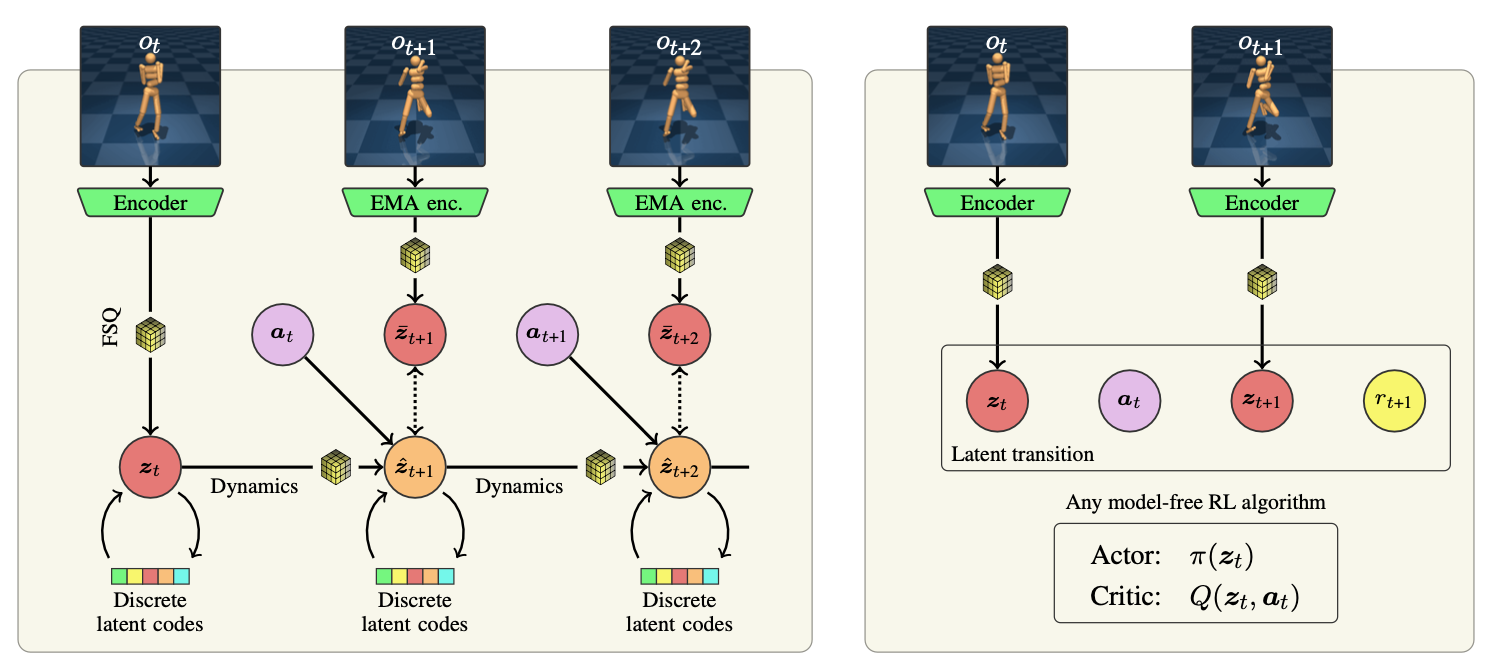
Learning representations for reinforcement learning (RL) has shown much promise for continuous control. We propose an efficient representation learning method using only a self-supervised latent-state consistency loss. Our approach employs an encoder and a dynamics model to map observations to latent states and predict future latent states, respectively. We achieve high performance and prevent representation collapse by quantizing the latent representation such that the rank of the representation is empirically preserved. Our method, named iQRL: implicitly Quantized Reinforcement Learning, is straightforward, compatible with any model-free RL algorithm, and demonstrates excellent performance by outperforming other recently proposed representation learning methods in continuous control benchmarks from DeepMind Control Suite.
@misc{scannell2024iqrl,
title = {iQRL - Implicitly Quantized Representations for Sample-efficient Reinforcement Learning},
author = {Aidan Scannell and Kalle Kujanpää and Yi Zhao and Mohammadreza Nakhaei and Arno Solin and Joni Pajarinen},
year = {2024},
eprint = {2406.02696},
archivePrefix = {arXiv},
primaryClass = {cs.LG}
}@inproceedings{scannellQuantized2024,
title = {Quantized Representations Prevent Dimensional Collapse in Self-predictive {RL}},
booktitle = {ICML Workshop on Aligning Reinforcement Learning Experimentalists and Theorists ({ARLET})},
author = {Aidan Scannell and Kalle Kujanpää and Yi Zhao and Mohammadreza Nakhaei and Arno Solin and Joni Pajarinen},
year = {2024},
} ), using only a self-supervised latent-state consistency loss, i.e. no decoder. Making the latent representation discrete with an implicit codebook (
), using only a self-supervised latent-state consistency loss, i.e. no decoder. Making the latent representation discrete with an implicit codebook ( ) contributes to the very high sample efficiency of iQRL and empirically prevents dimensional collapse.
) contributes to the very high sample efficiency of iQRL and empirically prevents dimensional collapse.